
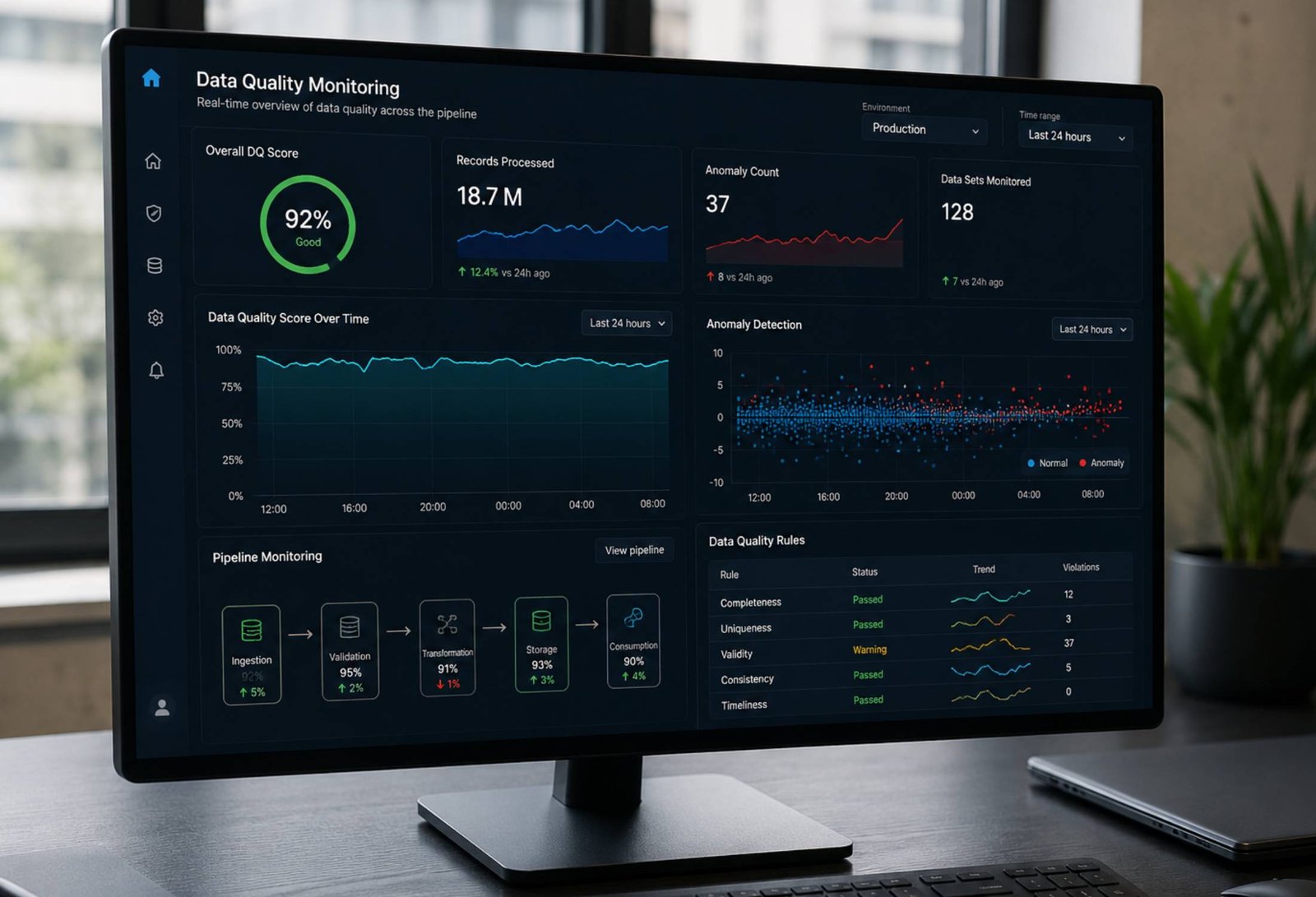
In today’s data-driven organisations, quality cannot be treated as a periodic audit exercise. Data quality is dynamic — it shifts with every pipeline run, every upstream schema change, and every new data source brought on board. Real-time data quality monitoring frameworks are no longer a luxury reserved for the most mature data teams; they are a foundational requirement for any organisation that depends on timely, accurate data to make decisions.
Why Static Data Quality Checks Are No Longer Enough
Traditional approaches to data quality relied on scheduled batch validation: run a suite of checks overnight, review a report in the morning, and fix issues before the business day begins. This model breaks down entirely when pipelines run continuously, when machine learning models consume data in real time, and when operational decisions depend on data freshness measured in seconds rather than hours.
The core quality dimensions — accuracy, completeness, consistency, and timeliness — demand continuous monitoring, not periodic snapshots. A completeness check that runs at midnight offers no protection against a broken ingestion job that fails at 9am and silently propagates nulls into downstream reports for hours before anyone notices.
Shift-Left Validation: Catching Issues at Ingestion
One of the most impactful strategies in modern data quality frameworks is shift-left validation — the practice of enforcing quality rules as close to the data source as possible, ideally at the moment of ingestion. Rather than discovering that a supplier feed contained malformed records only after those records have propagated through five transformation layers, shift-left approaches intercept and quarantine bad data at the pipeline boundary.
Shift-left validation typically combines schema enforcement (rejecting records that violate expected types or formats), statistical profiling (comparing incoming distributions against historical baselines), and business rule checks (ensuring domain-specific constraints are met before data is accepted). The earlier bad data is caught, the lower the remediation cost — both in engineering hours and in the erosion of stakeholder trust.
Machine Learning Anomaly Detection vs. Rigid Thresholds
Rule-based threshold monitoring has a fundamental limitation: it requires engineers to anticipate every failure mode in advance. Set a threshold too tight and the system floods on-call channels with false positives. Set it too loose and genuine data degradation slips through undetected.
Machine learning anomaly detection addresses this by learning what ‘normal’ looks like for each dataset, column, and pipeline — and flagging deviations from that learned baseline automatically. Rather than triggering alerts only when a missing-value rate crosses 5%, an ML-powered quality monitor understands that this particular feed always has elevated nulls on weekends and adjusts expectations accordingly.
Advanced frameworks correlate quality signals across multiple dimensions simultaneously: missing value rates, format violation frequencies, referential integrity failures, and semantic drift — where data values remain technically valid but have shifted in meaning. This multi-signal approach dramatically improves the signal-to-noise ratio of quality alerting systems.
Integrated Data Quality Dashboards Across the Pipeline
Quality issues do not respect pipeline boundaries. A degraded source dataset will propagate its problems through every transformation layer, ultimately corrupting dashboards, reports, and ML model inputs that sit at the far end of the pipeline. Effective real-time monitoring frameworks therefore require end-to-end visibility, surfacing quality scores at every stage from source ingestion through to data consumers.
Integrated quality dashboards give data engineers and data stewards a unified view of pipeline health, enabling proactive remediation before downstream consumers are affected. The best implementations link quality alerts directly to lineage graphs, so that when an anomaly is detected on a column, the team can immediately understand which reports, models, or business processes are at risk.
Balancing Precision and Volume: Adaptive Thresholds
Perhaps the most persistent challenge in data quality monitoring is the tension between precision and volume. Overly sensitive monitoring systems generate so many alerts that teams begin to ignore them — the data quality equivalent of alarm fatigue in a hospital. Yet frameworks tuned for low noise risk missing genuine quality degradation until it reaches business-critical severity.
Adaptive thresholds, tuned by actual usage patterns and historical behaviour, offer the most effective path through this tension. Rather than applying uniform sensitivity across all datasets, adaptive frameworks weight quality monitoring intensity by business criticality: tighter tolerances on datasets feeding executive dashboards, looser tolerances on exploratory data science sandboxes. This usage-driven approach ensures monitoring resources are concentrated where data quality failures carry the highest cost.
Does Your Monitoring Evolve With Data Velocity?
As data pipelines grow more complex and data volumes scale, a question every data leader must honestly answer is: does your quality monitoring evolve with data velocity, or does it lag behind business needs? Many organisations find themselves running the same static checks they implemented three years ago against pipelines that have tripled in complexity — and wondering why data trust continues to erode.
A mature real-time data quality framework is not a one-time implementation. It requires continuous refinement of detection rules, regular reassessment of threshold sensitivity, and ongoing integration with new data sources and pipeline components as the architecture evolves.
Audit Your Data Quality Framework with GovernData
GovernData audits existing data quality frameworks and benchmarks them against industry best practices — identifying gaps in coverage, opportunities to introduce ML-based anomaly detection, and strategies for implementing shift-left validation across your pipelines.
Schedule your review today and build a quality monitoring framework that scales with your data, not against it.


